

Data / IA
Serverless, IA, Lakeflow, open source… Toutes les annonces du Databricks Summit 2024
Par Laurent Delattre, publié le 18 juin 2024
À l’occasion de son « Data + AI Summit 2024 », Databricks a multiplié les annonces et démontré sa capacité à innover pour mieux se démarquer non seulement de Snowflake mais aussi des Data fabriques des hyperscalers.
Fondée par les créateurs d’Apache Spark, la plateforme Databricks s’est imposée au fil des années comme l’une des plateformes Data Cloud les plus importantes du marché et comme le principal concurrent de Snowflake. Les deux éditeurs ont d’ailleurs depuis quelque temps une fâcheuse tendance à aligner leurs stratégies et à se renvoyer la balle.
À l’occasion de sa conférence « Data + AI Summit 2024 », Databricks a littéralement appuyé sur l’accélérateur pour réinventer sa plateforme et bouleverser le paysage de l’analyse des données et de l’IA dans les entreprises. L’éditeur a multiplié les annonces pour non seulement répondre aux dernières innovations de Snowflake mais également proposer une alternative multicloud aux plateformes de données des hyperscalers.
Voici ce qu’il faut retenir des annonces du Databricks Data + AI Summit 2024 :
1 – Databricks passe en full serverless
S’il est un défaut majeur de Databricks, c’est bien sa complexité de mise en œuvre. Pas du côté stockage qui est très fluide quelque soit le cloud hébergeur mais bien du côté du Compute et de la création des clusters. Car – contrairement à d’autres – seules certaines fonctionnalités sont serverless, l’essentiel nécessitant des administrateurs et compétences pour mettre en place l’infrastructure IaaS nécessaire.
Le 1er juillet prochain, ce défaut – majeur – n’en sera plus un. C’est la grande annonce de ce « Summit ». Databricks devient 100% Cloud et 100% Serverless. « À partir du 1er juillet, tout Databricks sera disponible en mode Serverless qu’il s’agisse de nos notebooks ou de nos clusters Spark, qu’il s’agisse des flux de travail, du traitement des tâches, de tous les différents aspects de la plateforme » explique ainsi Ali Ghodsi, le CEO de Databricks.
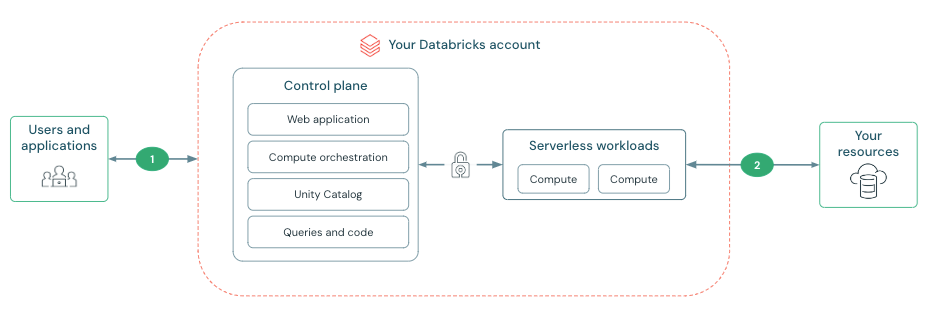
Et ça change toute la donne : « Aujourd’hui, vous payez pour du temps d’inactivité, en réalité, vous payez les fournisseurs de cloud et vous nous payez en plus, même en période d’inactivité. Avec le serverless, vous ne payez que pour ce que vous utilisez. En fait, il n’y a pas de cluster à configurer… nous nous occupons de tout pour vous en arrière-plan. Et une chose qui nous enthousiasme, c’est que nous possédons maintenant toutes les machines. Ce n’est plus cette responsabilité conjointe sur des machines qui fonctionnent dans votre compte et dans le nôtre. … Vous pouvez vraiment faire le suivi et le marquage, et vous pouvez vraiment utiliser l’IA pour prédire où vos coûts vont aller dans l’infrastructure serverless » ajoute Ali Ghodsi.
Pour ainsi transformer son infrastructure, Databricks a profondément repensé sa plateforme et lourdement investit. L’éditeur encourage désormais tous ses clients à basculer dans ce mode. Et prévient qu’à l’avenir, les nouveaux services et fonctionnalités ne seront probablement disponibles qu’en mode serverless !
2 – Le rachat de Tabular pour mettre fin à la guerre des formats
Avec les data cloud est née une guerre. Celle des formats de données utilisés pour la gestion des données dans les lakehouses (ces datawarehouses next gen reposant sur des lacs de données). L’objectif est que les données soient stockées complètement indépendamment du « compute » nécessaire à leur gestion, afin que toute entreprise reste vraiment maître de ses données, stockées dans des data lakes les plus basiques possibles.
Databricks et Snowflake s’opposent ainsi depuis des années sur un format universel concrétisant cette vision. Snowflake en soutenant Apache Iceberg, Databricks en soutenant son projet « Delta Lake ». « En lançant l’idée de Delta Lake il y a quelques années, nous voulions proposer une sorte de format ‘USB’ pour la donnée et l’IA où chacun pourrait ensuite venir connecter sa plateforme de données comme si on connectait une clé USB contenant le moteur de données à ces données stockées dans le cloud. Et ceci permet de multiplier les cas d’usage, puisque vous pouvez utiliser plusieurs moteurs différents pour satisfaire différents besoins. »
Ainsi, selon Databricks, 92% de toutes les données qu’il gère passent par Delta. Soit 4 exaoctets de données par jour !
Pour mettre un terme à cette guerre de format entre Delta Lake, Iceberg et d’autres formats concurrents comme Hudi, Databricks a proposé un format universel « UniForm » l’an dernier mais vient surtout d’acquérir – pour un milliard de dollars – l’éditeur Tabular, spécialiste des technologies Iceberg et startup fondée par les créateurs d’Iceberg. L’idée est d’unifier les formats et masquer les différences d’implémentation aux développeurs.
3 – L’Unity Catalog devient open source
Il est un autre domaine où Databricks et Snowflake sont en forte compétition. Celui des catalogues de métadonnées utilisés pour gérer et organiser les informations sur les données stockées dans leurs systèmes et pour les différents moteurs de calcul. Il y a environ un mois, Snowflake a lancé son Polaris Catalog, un catalogue pour Apache Iceberg que l’éditeur compte publier en open source à la rentrée.
De son côté, Databricks dispose de son propre Unity Catalog au-dessus de Delta Lake qui outre l’aspect métadonnées offre des fonctions de contrôle d’accès, d’audit, de traçabilité, de découverte de données et de gestion des stratégies d’accès.
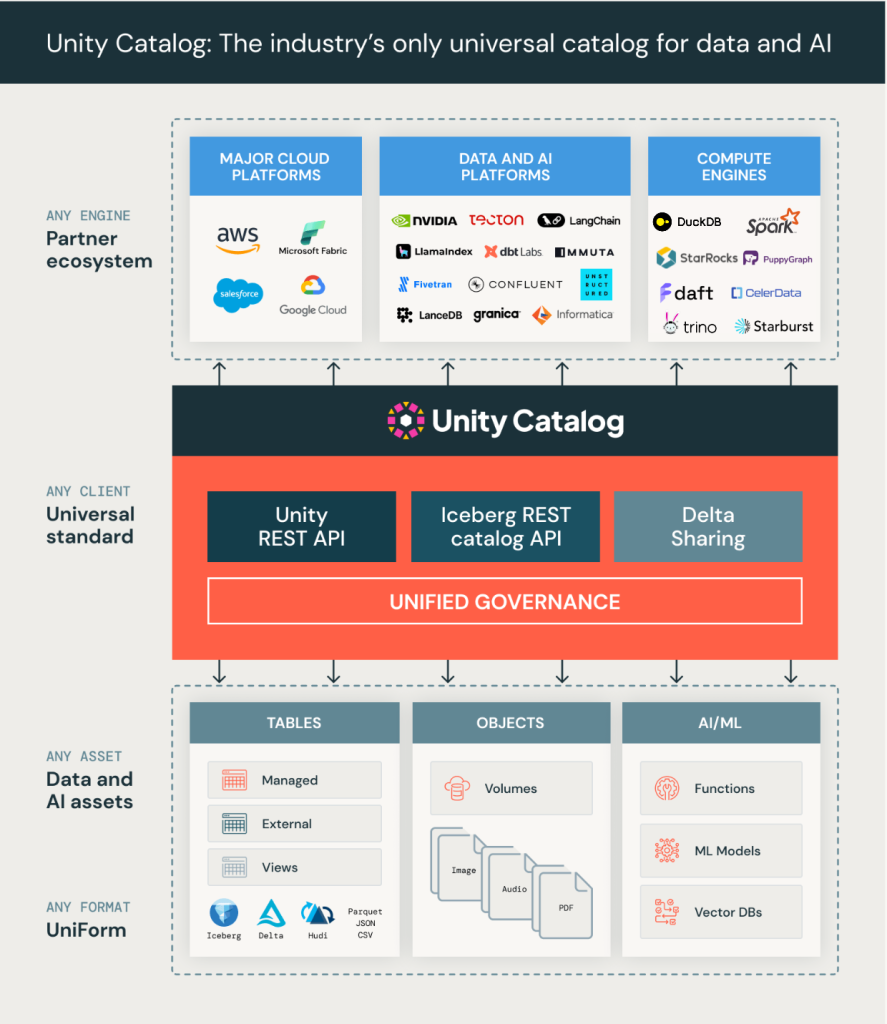
À l’occasion de son Summit 2024, Databricks a annoncé la publication en open source de son Unity Catalog sous licence Apache 2.0 ainsi que l’ouverture de toutes ses APIs. Histoire de prendre de l’avance sur Snowflake, cette publication des codes sources a été faite en live durant la conférence.
Dit autrement, la guerre des formats dérive désormais vers une guerre des catalogues de données entre les deux acteurs.
4 – Toujours plus d’IA grâce à Mosaic AI
L’IA est au cœur des préoccupations des entreprises et aucune plateforme de données modernes ne peut se passer d’outils pour aider à construire, déployer et surveiller les modèles ML et IA génératives.
Chez Databricks, la trousse à outils IA se nomme « Mosaic AI ». Elle simplifie l’intégration des données dans le cycle de vie des modèles, la personnalisation des modèles, l’entrainement des modèles, la création d’applications IA et le suivi des déploiements.
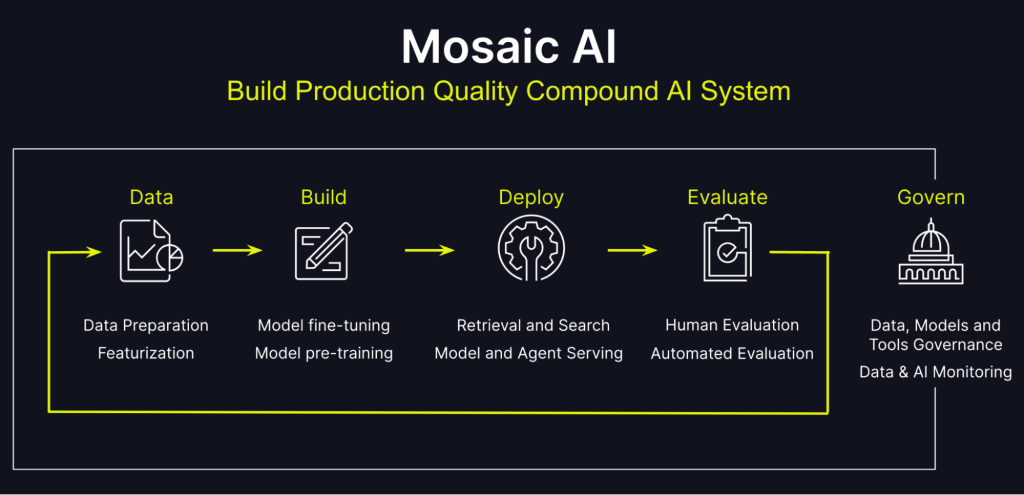
À l’occasion de son Summit 2024, Databricks a annoncé cinq nouveautés au sein de Mosaic AI :
* Mosaic AI Model Training : un nouveau service serverless (dopé par des GPU NVidia H100) pour former et personnaliser les LLM et autres modèles génératifs avec vos propres données.
* Mosaic AI Agent framework : un outil qui simplifie la création d’agents intelligents en combinant des LLM, la recherche vectorielle (Mosaic AI Vector Search) de la plateforme Databricks et les techniques RAG (génération augmentée par récupération).
* Mosaic AI Agent Evaluation : pour évaluer les qualités des agents créés avec l’outil précédent, Databricks lance un service d’évaluation qui permet de tester les performances et la qualité des réponses des agents en production en combinant des IA à base de LLM mais aussi les retours d’expérience des utilisateurs avec possibilité de leur faire étiqueter les jeux de données.
* Mosaic AI Tools Catalog : un outil pour gouverner, partager et découvrir des outils IA au sein de l’organisation au travers d’Unity Catalog.
* Mosaic AI Gateway : ce service est présenté par Databricks comme « une interface unifiée pour interroger, gérer et déployer n’importe quel modèle open source ou propriétaire ». L’idée est de disposer d’une passerelle qui centralise toutes les interrogations des LLM dans le cloud de manière contrôlée pour éviter la fuite d’informations sensibles ou les usages inappropriés. L’outil permet aussi de contrôler les coûts en surveillant les usages et les appels aux modèles payants.
5 – Databricks AI/BI ou la BI dopée à l’IA
Dans l’univers de la data, on a tendance à distinguer d’un côté l’analytique décisionnelle (avec ce qu’on appelle la BI ou Business Intelligence) et l’IA. Mais pourquoi donc ? Les deux ne s’opposent pas et se complètent.
Alors, pourquoi ne pas utiliser l’IA générative pour justement démocratiser l’accès à la BI, aux analyses de données et aux insights business ? C’est exactement le but poursuivi par « Databricks AI/BI » le nouveau service annoncé à l’occasion de Summit 2024.
Databricks AI/BI comporte deux interfaces :
– “AI/BI Dashboards”, une solution pour créer des tableaux de bords en Low-Code à l’aide d’IA.
– “AI/BI Genie”, une interface conversationnelle pour discuter avec les données et obtenir des réponses en langage naturel.
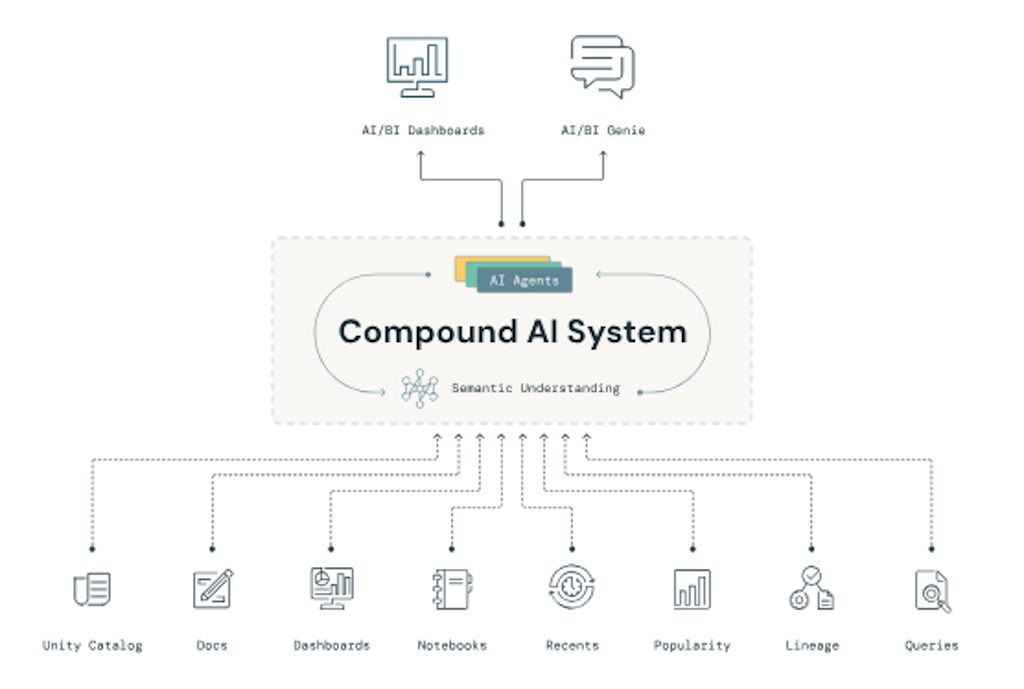
Toute la solution Databricks AI/BI repose en réalité sur des agents spécialisés qui traitent les questions métier/business et génèrent des réponses en langage naturel associées à des visualisations parlantes. Ces agents sont responsables de tâches spécifiques telles que la planification, la génération SQL, l’explication des données, la visualisation et la certification des résultats. Databricks AI/BI est disponible pour tous les clients Databricks SQL Pro et Serverless.
6 – Databricks lance LakeFlow pour simplifier les pipelines de données
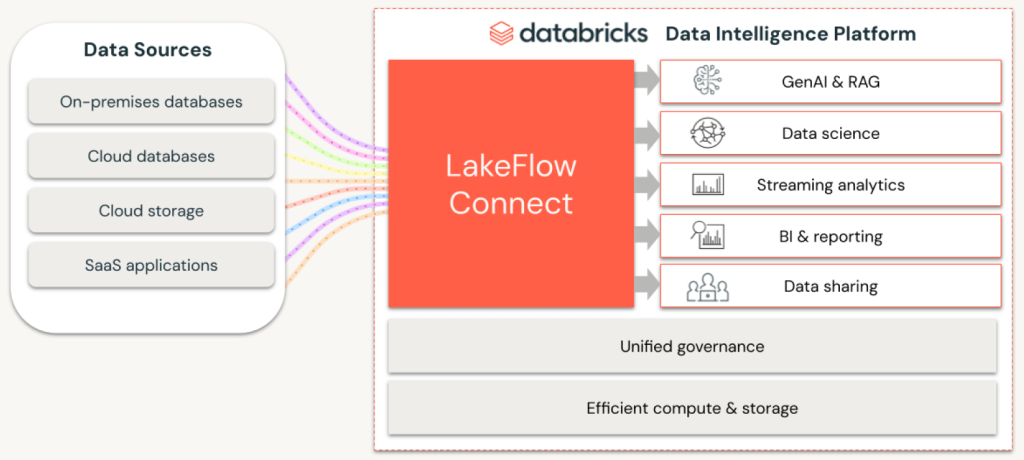
Dernière grande annonce de Databricks sur ce Summit 2024, LakeFlow est la solution maison d’ingénierie de données qui permettra aux utilisateurs de construire des pipelines de données et d’ingérer des données à partir de diverses sources.
Jusqu’ici Databricks ne disposait pas de solution d’ingestion des données ELT et se reposait sur des partenaires comme Fivetran ou Rudderstack pour toutes les tâches liées à la préparation, transformation et chargement des données.
LakeFlow est désormais la solution officielle de Databricks pour l’ingestion, la transformation et l’orchestration de données même si l’éditeur veut continuer à soutenir ses anciens partenaires (qui peuvent toujours se prévaloir de leur grande richesse de connecteurs et de la maturité de leur offre).
Le service se compose de LakeFlow Connect pour les connecteurs, LakeFlow Pipelines pour la transformation de données en SQL ou Python, et LakeFlow Jobs pour l’orchestration automatisée. Selon Databricks, la création de LakeFlow se justifie par une demande pressante de ses clients afin de réduire les coûts et consolider les services utilisés.
LakeFlow Connect sera le premier module disponible en preview. Les autres arriveront plus tard dans l’année.
Au final, que faut-il retenir de ce Databricks Summit 2024 ? Beaucoup d’annonces mais surtout une folle énergie pour enrichir la solution cloud et en faire une des plateformes de données les plus modernes. Avec une constatation qui se dessinait depuis quelque temps : Databricks et Snowflake sont désormais en totale concurrence, avec des trajectoires extrêmement similaires. Parallèlement, les hyperscalers avancent eux aussi à grands pas notamment Microsoft avec sa Microsoft Fabric, mais également Google avec son ensemble « BigQuery, BigLake, BigTable, Vertex AI, Looker Studio, Composer, DataStream, DataFlow, DataPlex, etc. ». La guerre des cloud data platforms ne fait que débuter…
À LIRE AUSSI :
À LIRE AUSSI :











