

Data / IA
Mistral lance de nouveaux « mini » modèles IA
Par Laurent Delattre, publié le 17 octobre 2024
Conçus pour une exécution en local sur les Copilot+ PC, le Edge ou l’embarqué, les nouveaux modèles « Ministraux » de Mistral AI démontre le potentiel des nouveaux mini-modèles IA conçus pour une inférence en local sur tous types de terminaux mobiles.
Il y a un an, la startup française Mistral AI dévoilait son Mistral 7B au potentiel révélateur. Avec Mistral 7B, le monde découvrait en effet que bien des cas d’usage d’entreprises seraient mieux servis par de petits modèles LLM exécutés dans leurs propres datacenters que par des gigantesques LLM frontières dans le cloud.
Depuis, Mistral AI a certes poursuivi ses efforts sur les grands modèles, avec « Large 2 » par exemple, mais a surtout travaillé à sans cesse améliorer et optimiser des modèles pour les rendre plus compacts au point de pouvoir parfois être directement exécutés sur les NPU qui envahissent les processeurs des smartphones, des tablettes et des Copilot+ PC.
Après les récentes présentations de Mistral NeMo, Pixtral, Codestral Mamba et Mathstral, la startup dévoile la dernière itération de ses efforts d’optimisation avec le lancement d’une nouvelle famille de modèles SLM baptisée « Les Ministraux ». Elle vise à répondre à une demande croissante pour des solutions d’IA locales et respectueuses de la vie privée. La famille comporte pour l’instant deux modèles : Ministral 3B et Ministral 8B.
Tous deux disposent d’une fenêtre de contexte de 128 000 tokens (soit environ une cinquantaine de pages de texte). Ministral 8B intègre un modèle d’attention à fenêtre glissante entrelacée pour une inférence plus rapide et plus économe en mémoire. Ces deux modèles peuvent être utilisés pour diverses applications, allant de la génération de texte basique à la traduction en passant par la collaboration avec des modèles plus puissants pour accomplir des tâches complexes.
« Ces modèles établissent de nouvelles frontières en termes de connaissances, de bon sens, de raisonnement, d’appel de fonctions et d’efficacité dans la catégorie des modèles génératifs de moins de 10 milliards de paramètres » explique la jeune pousse française. « Ils peuvent être directement utilisés ou affinés (fine-tunés) pour une variété d’applications, allant de l’orchestration de flux de travail autonomes à la création d’Agents IA spécialisés pour des tâches spécifiques ».
Mistral AI met en avant les avantages de ces modèles pour des scénarios tels que la traduction en local sur l’appareil, les assistants intelligents fonctionnant sans connexion Internet, l’analyse de données locale et la robotique autonome. Le modèle Ministral 8B est d’ores et déjà téléchargeable à des fins de recherche, tandis que son utilisation commerciale nécessite l’obtention d’une licence auprès de la startup.
Les développeurs peuvent également accéder à ces modèles via l’API de la plateforme cloud de Mistral, « La Plateforme », ainsi que sur d’autres services cloud partenaires dans les semaines à venir. Le coût d’utilisation est fixé à 10 centimes par million de jetons (en entrée comme en sortie) pour Ministral 8B et 4 centimes seulement pour Ministral 3B.
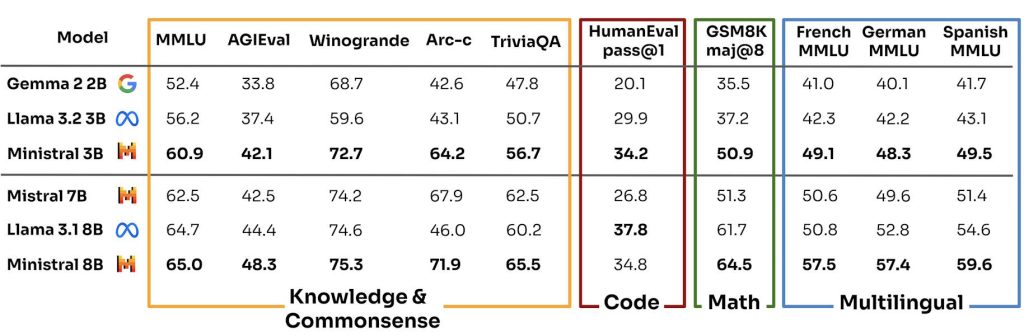
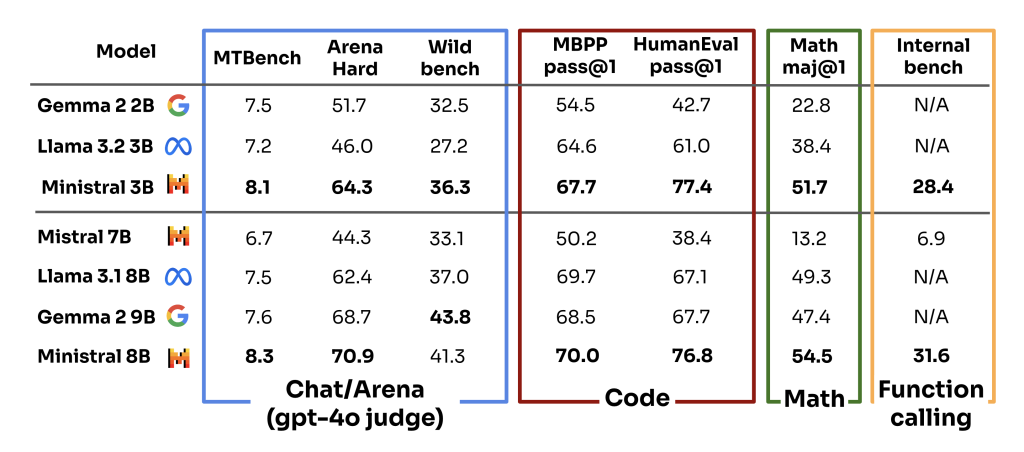
Cette initiative s’inscrit dans une tendance plus large du secteur vers des modèles d’IA plus petits, plus efficaces, et aisément « fine-tunables » (autrement dit personnalisables) comme en témoignent les récentes annonces de Google avec sa famille Gemma et de Microsoft avec sa collection Phi. Mistral AI affirme que ses nouveaux modèles surpassent leurs concurrents sur plusieurs critères d’évaluation de l’IA. La startup rappelle surtout les progrès réalisés en 1 an. En effet, son modèle Ministral 3B (notamment en mode “fine-tuné”) égale voire surclasse l’ancien et populaire Mistral 7B sur à peu près tous les plans et tous les tests !
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











