


Data / IA
Data-cloud : Google et Microsoft alignés sur la même trajectoire
Par Marie Varandat, publié le 12 octobre 2022
Une IA toujours plus accessible et performante avec des fonctionnalités nécessitant toujours moins de compétences en développement, le tout enrobé d’efforts pour intégrer et gouverner toutes les sources de données de l’entreprise… à l’ère du data-driven, Google et Microsoft adoptent des recettes très similaires pour attirer les entreprises vers leur plateforme data cloud.
L’époque où il fallait 12 experts et trois ans de mise en œuvre pour donner naissance à une application BI est définitivement révolue. Aujourd’hui, on programme des IA en langage naturel, on brise les silos de données sur un clic de souris, on multiplie les entrainements de modèles ML et on automatise les processus à gogo… C’est du moins le sentiment que l’on pourrait tirer des annonces effectuées par Google et Microsoft lors de leurs grandes conférences, respectivement Google Next’22 et Ignite 2022, qui ont toutes deux lieues cette semaine.
Au programme beaucoup d’annonces pour la plupart mineures mais avec un réel impact sur la facilité avec laquelle les entreprises vont pouvoir exploiter leurs données pour gagner en productivité, en sécurité ou encore en pertinence. Et, aussi concurrents que puissent être ces deux grands leaders de l’ère du cloud computing, difficile d’ignorer à quel point leur stratégie axée autour d’exploitation de la data est extrêmement similaire.
Simplifier l’exploitation de la data
À l’ère de l’entreprise data-driven, tout comme Google, Microsoft se focalise sur l’exploitation de la donnée. Simplifier les développements, faciliter l’accès, briser les silos, optimiser la gouvernance, monter en puissance sur les services IA… le tout articulé autour d’une plateforme qui centralise le stockage et les services.
Chez Microsoft, elle s’appelle Azure Synapse et elle est cœur de son « Intelligent Data Platform ».
Chez Google, c’est BigQuery qui focalise tous les services, qu’il s’agisse d’IA, de ML ou encore de BI dans une offre de data-cloud.
À LIRE AUSSI :
Les deux grands acteurs du cloud visent avant tout l’accessibilité de la donnée. Elle se traduit par des fonctions no-code pour créer des pipelines de données ou encore des tableaux de bord par des utilisateurs finaux n’ayant pas de compétences particulières en programmation. Elle se concrétise aussi par toujours plus de facilité d’accès à une multitude de services ML et AI, qu’il s’agisse de vision par ordinateur, de traduction automatique, de résumés de documents élaborés par l’IA, d’extraction d’informations pertinentes de documents non structurés, etc.
Plus performants et plus multilingues, ces services s’enrichissent de bibliothèques de modèles pré-entrainés. Avec son nouveau service Vertex IA Vision Google cible le secteur de l’industrie et du retail. Microsoft n’est pas en reste avec Computer Vision qui accueille Image Analysis 4.0 and Spatial Analysis on the Edge, deux nouvelles fonctionnalités pour mieux exploiter le patrimoine d’images des entreprises et exploiter les flux vidéo captés par des caméras en environnement industriel, urbain ou encore dans des entrepôts, magasins, etc.
Accélérer les projets analytiques, IA et ML
Parallèlement, les deux acteurs travaillent sur l’accélération des projets data. D’un côté Microsoft Project Bonsai, plateforme low-code qui s’enrichit d’outils pour accélérer les entrainements et mieux contrôler le comportement des IA et des systèmes automatisés. De son côté, Google unifie ses technologies ML et IA sous la bannière Looker, à commencer par Looker Data Studio qui simplifie la conception de rapports, et ajoute une interface Drag & Drop à son environnement de développement ML/IA Vertex IA.
À LIRE AUSSI :

Et, dans un vaste chantier d’annonces à donner le tournis, les deux acteurs n’oublient pas qu’ils sont aussi éditeurs d’une suite collaborative. Tandis que Microsoft simplifie l’intégration de données provenant de sa suite bureautique à son « Intelligent Data Platform » avec Mapping Data Flows, un modèle pour créer des flux d’alimentation en quelques clics, Google interface à sa suite Workspace à Looker mais également Tableau et PowerBI.
Fédérer toujours plus de partenaires
Autre similitude, Google qui ambitionne de devenir « le data cloud le plus ouvert du marché » multiplie comme Microsoft les intégrations avec les solutions data du marché.
Dans cette perspective, le premier vient de créer la Data Cloud Alliance qui réunit 17 partenaires dont Accenture, Deloitte, mais aussi Databricks, Dataiku, Collibra, MongoDB, Informatica ou encore Elastic et bientôt ServiceNow.
De son côté, Microsoft revendique un écosystème de partenaires incluant MongoDB et YugabyteDB dans le domaine des bases de données, Informatica, Confluent, dbt Labs, Fivetran, Qlik et Striim pour l’intégration, la transformation et l’analyse low-code/no-code sans oublier la gouvernance des données représentée par Profisee, CluedIn, Delphix et OneTrust.
À LIRE AUSSI :

De fait, cette stratégie de partenariats répond non seulement au besoin de briser les silos de données en prenant en compte toutes les technologies présentes dans l’entreprise mais également à l’essor du multicloud qui suppose des solutions d’intégration clef en main pour exploiter mais aussi gouverner les données éparpillées entre différents clouds, qu’ils soient publics ou privés.
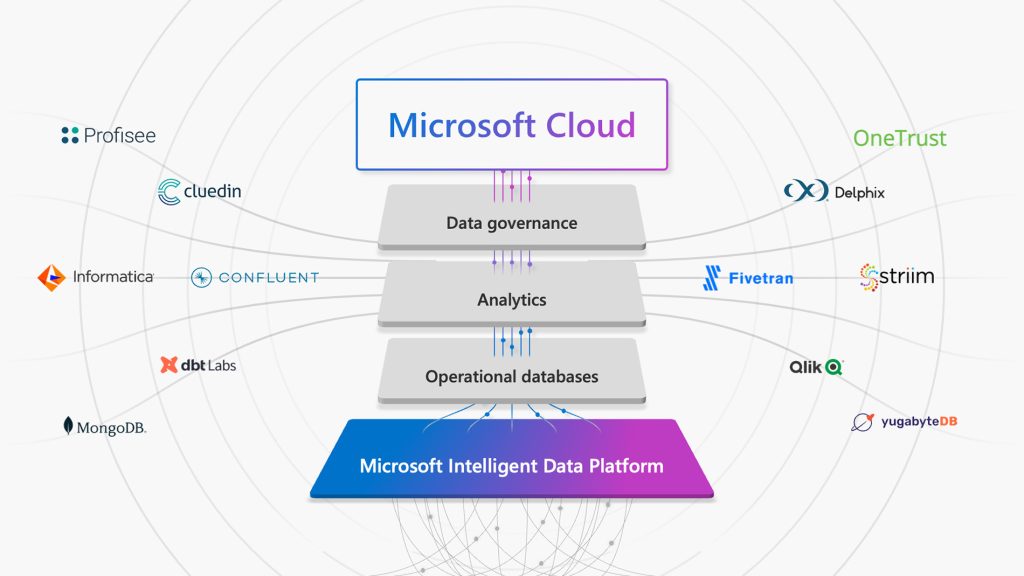
Dans ce domaine, les deux acteurs ne lésinent d’ailleurs pas sur leurs efforts. Au-delà des partenariats, ils mettent aussi la main à la pâte, Microsoft annonçant par exemple à Ignite le support de PostgreSQL à sa base ultra distribuée Azure Cosmos DB ou encore la possibilité de migrer les bases Oracle vers les bases Azure avec Azure Data Studio.
Pour sa part, Google annonce à Next’22 gèrer plus 800 sources de données et proposer plus de 600 connecteurs avec Looker tandis que BigQuery – qui gère désormais les données non-structurées – accueille de nouveaux outils pour analyser les données non-structurées en streaming et accepte de nouveaux formats (Apache Iceberg, Linux Foundation Delta Lake et Apache Hudi) tout en jouant la carte de l’intégration avec Apache Spark.
Nul doute que ces stratégies d’accessibilité, d’accélération et d’intégration pour faciliter la mise en place d’applications analytiques, ML et IA répondent aux besoins du marché. Selon une étude Splunk c’est même la principale attente de toutes les entreprises qui cherchent à innover en capitalisant sur leurs données. Légèrement à la traine dans ce domaine avec seulement 9% d’entreprises qui exploitent 71% à 80 % de leurs données, les organisations françaises ne peuvent donc que bénéficier d’un data-cloud plus ouvert et riche en fonctionnalités pour les aider à exploiter sur leur patrimoine d’informations.










