


Data / IA
GPT-4o mini & Mistral NeMo : les petits modèles s’imposent
Par Laurent Delattre, publié le 19 juillet 2024
OpenAI annonce « GPT-4o mini ». Parallèlement, Mistral AI lance « Mistral NeMo » en collaboration avec NVidia. Deux nouveaux « petits » LLM pourtant très agiles mais surtout bien plus économiques pour les entreprises comme pour la planète !
Les petits modèles sont en vogue. On ne parle même presque plus que d’eux depuis le début de l’année. Certes, les grands modèles comme Gemini Pro, GPT-4o, Claude 3.5 Sonnet avec leurs centaines de milliards de paramètres ne disparaîtront pas de sitôt. Néanmoins les petits modèles – souvent spécialisés dans une langue ou un domaine –, portés par des startups comme LightOn (avec Alfred LLM) et Mistral AI (avec Mistral 7B et Mistral Small), ont largement démontré leur potentiel notamment pour satisfaire des cas d’usage bien spécifiques et bornés.
Les petits modèles, composés de milliards voire dizaines de milliards de paramètres, se sont révélés tout à fait capables et peuvent même aujourd’hui être multimodaux. Bien « formés » avec les bons jeux de données et bien « fine-tunés » avec les bons outils et les bons paramètres, ils peuvent dans certains cas rivaliser avec les LLM à centaines de milliards de paramètres. Surtout, ils sont moins onéreux à entraîner et à inférer et donc moins onéreux pour les entreprises qui les exploitent. Réclamant moins de ressources, ils sont aussi plus alignés sur les efforts « numérique responsable » des organisations.
Après Microsoft Phi-3 ou Google Gemma 2, voici venir deux nouveaux petits modèles de langage en provenance de deux acteurs majeurs du marché : OpenAI avec « GPT-4o mini » et Mistral AI avec Mistral NeMo.
OpenAI GPT-4o mini, pour remplacer GPT 3.5 Turbo en mieux…
Cette semaine, OpenAI a dévoilé « GPT-4o mini » présenté comme le plus efficient des petits modèles de la startup. « Nous pensons que GPT-4o mini va considérablement élargir le spectre des applications à base d’IA en rendant l’intelligence artificielle bien plus abordable » explique l’éditeur.
OpenAI se garde bien de préciser la taille réelle de son « SLM » (Small Language Model) et le nombre de paramètres. Mais selon la startup, GPT-4o mini obtient un score de 82% sur les benchmarks MMLU et surpasse son ancien GPT-4 lors des tests de chat réalisés sur la plateforme comparative LMSYS. Or son tarif est infiniment plus accessible : 15 cents par million de tokens en entrée et 60 cents par million de tokens en sortie. C’est 60% moins cher que ce qui était jusqu’ici le plus accessible des LLMs : GPT-3.5 Turbo.
Un GPT-3.5 Turbo qui a régné en maître au premier semestre 2023 sur l’univers des IA et qui tire donc désormais sa révérence, remplacé sur la plateforme d’OpenAI par un « GPT-4o mini » beaucoup plus agile, plus pertinent, moins cher, et moins gourmand en ressources et en énergie. Bien évidemment, “GPT-4 Omni” (plus connu sous le nom GPT-4o) reste le modèle le plus évolué d’OpenAI en attendant la prochaine génération peut-être d’ici la fin de l’année (GPT-5?).
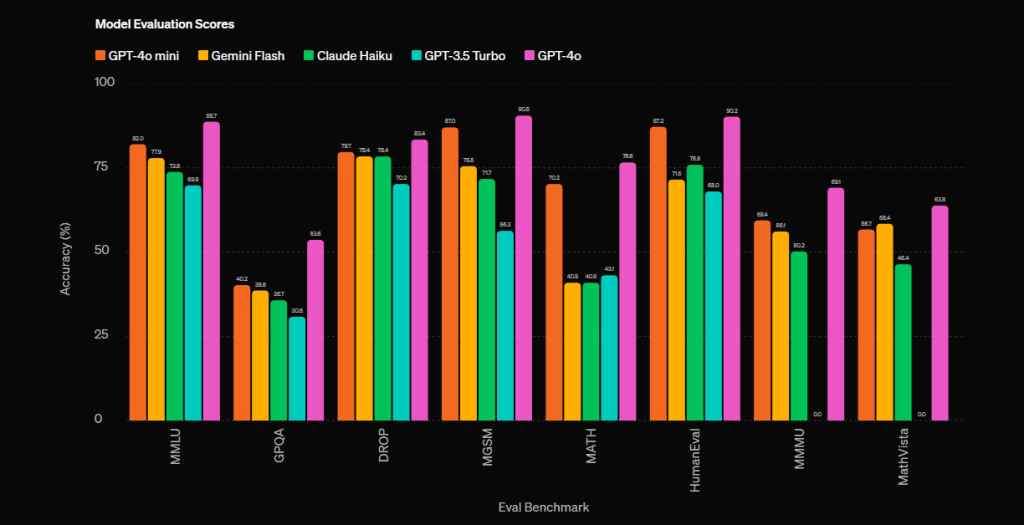
Selon OpenAI, « GPT-4o mini » surpasse à la fois en « intelligence textuelle » et en raisonnement les autres « petits modèles » du marché comme Gemini Flash et Claude Haiku. Mais GPT-4o Mini est aussi un modèle multimodal qui accepte textes, images, sons et vidéos en entrée et pourra prochainement produire des réponses multimodales.
GPT-4o mini dispose d’une fenêtre contextuelle de 128.000 Tokens et sa base de connaissance s’arrête à Octobre 2023.
Mistral NeMo, le nouveau modèle phare SLM de Mistral AI
Décidément très active, Mistral AI répond du tac au tac à OpenAI avec un nouveau modèle. L’éditeur qui avait déjà lancé Mathstral et Codestral Mamba en début de semaine annonce son nouveau « SLM » à l’état de l’art : Mistral NeMo. Publié en open-source sous licence 2.0, Mistral NeMo est un modèle à 12 milliards de paramètres (qui peut donc typiquement être inférés en local sur des machines à NPU comme les Copilot+ PC), doté d’une fenêtre contextuelle de 128.000 tokens et destiné à rapidement remplacer Mistral 7B sur le marché.
Selon Mistral, NeMo surclasse des modèles comme Gemma 2 9B et LLama 3 8B dans la grande majorité des tests. Multilingue, NeMo est particulièrement pertinent en Anglais, Français, Allemand, Espagnol, Portugais et Italien mais aussi en Chinois, Japonais, Coréen, Arabe et Hindi.
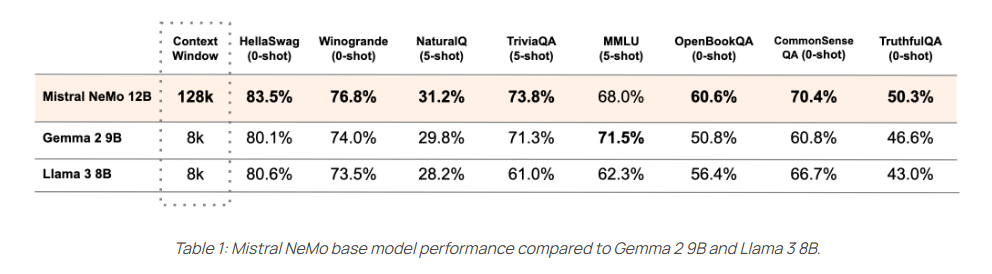
La particularité de NeMo est d’avoir été co-conçu en partenariat avec NVidia (NeMo a été entraîné en tenant compte de la quantification ce qui permet des inférences en FP8 sans perte de qualité) et d’exploiter un tout nouveau « tokenizer » dénommé « Tekken ». Basé sur Tiktoken, Tekken est entraîné sur plus de 100 langues et compresse le texte en langage naturel plus efficacement (d’environ 30%) que l’ancien tokenizer « SentencePiece » jusqu’ici utilisé par Mistral.
Outre la publication en open source du modèle pré-entraîné, Mistral publie également les points de contrôle qui permettent de « fine tuner » le modèle afin d’en accélérer son adoption aussi bien par les chercheurs en IA que par les entreprises en quête de modèles exécutables en local.
On le voit, les progrès en IA évoluent désormais dans deux axes différents. Les modèles LLM “frontières” qui font progresser la recherche en IA peu à peu vers l’intelligence générale (AGI) et les “petits mais costauds” modèles SLM qui répondent de mieux en mieux aux besoins des entreprises d’IA à la fois capables, pertinentes, peu coûteuses et exécutables sur leurs propres infrastructures voire sur leurs PC et smartphones…
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











